跟着ab尝试在互联网行业用户减少方面的实行,各家都搭建了本人的ab尝试平台(不限于BAT) 大概者 购买了ab尝试效劳。即日便来瞅下AB尝试的前生今世,能为企业处理什么问题,何如样尺度化ab尝试过程,何如样搭建一个ab尝试平台。

36Kr曾在一篇报道中写道:“头条发布一个新APP,其名字都必定挨N个包放到各大运用商场进行屡次A/B尝试而决定,弛一鸣奉告共事:哪怕你有99.9%的把握那是最佳的一个名字,测一下又有神马闭系呢?”
一、追本溯源
AB尝试的前身是随机闭于照考查-双盲尝试,是“调理/生物试验将探究闭于象随机分组,闭于不共组实行不共的搞预,闭于照起效验”。
双盲尝试中病人被随机分成二组,在不知情的情景下分别赋予安慰剂和尝试用药,经过一段时间的试验后再来比较这二组病人的展现是否具备明显的分别,从而决定尝试用药是否果然灵验。
2000年谷歌工程师进行了第一次AB Test,试图决定在搜寻引擎截止页面上表露的最佳截止数目。后来AB尝试连接展开,然而前提和基础规则常常保护不变,2011年,谷歌首次尝试后11年,谷歌进行了7,000屡次不共的AB尝试。
12年奥巴马竞选网站的款式,经过AB Test 找到了更能吸引捐献,帮帮奥巴马博得了更高的捐献金额。
AB Test将不共的用户分成不共的组,共时尝试不共的筹备,经过用户反应的简直数据来找出哪一个筹备更好的过程。处理的是“多种筹备须要拍脑袋确认哪一种更好的问题”。
二、个性
- 先验性:A/B Test 是一种“先验体系”,属于猜测型论断(与其相闭于的是后验型的体味归纳)。共样是一个筹备是否是非:A/B Test 经过小流量尝试赢得具备代表性的试验论断,来考订筹备是非后再决定是否实行到全量;后验型则是经过发布版本后的版本数据闭于比归纳赢得。
- 并行性:是指救济二个大概以上的试验共时在线,并须要保护其每个试验所处情况普遍。并行性极大的降低了多试验的时间成本。
- 科学性:AB Test是用科学的办法来考订筹备,科学性表姑且流量调配的科学性、统计的科学性。牢记在开篇提到的“AB尝试的前身是随机闭于照试验,调理/生物试验将探究闭于象随机分组,闭于不共组实行不共的搞预,闭于照起效验”,这乞求AB Test将好像特性的用户均匀的调配到试验组别中,保证每个组其他用户特性沟通。
三、统计学本理
3.1 抽样
总体:“是包括所探究的理想个别(数据)的集中,它常常由所探究的一些个别构成,如由多个企业产生的集中,多个住户户产生的集中,多部分产生的集中,等等”。闭于于一个app、web网站,他的十脚用户即为总体。
样品:与总相闭于应,是从总体中按必定比率抽取且能代表总体的局部个别集中。比方:分别抽样5%的app用户,产生试验组、闭于照组。
从总体到样品的过程,即为抽样。所以ABTest,是经过抽样 获得 试验组、闭于照组,闭于比统计量均值,以衡量试验效验。
抽样面对问题“何如样从一个总体中按必定比率抽取一组随机样品?”,也即是样品统计值是否不妨代表总体参数?
3.2 参数估计
为了估计总体参数,会估计样品的统计量,比方:某个优化目目标平稳值。而样品的统计截止为简直的总体统计截止的点估计,然而因为点估计树值与总体参数值在某种程度上存留分别。不妨构造区间估计以便获得闭于点估计值与总体参数的分别大小的信息。区间估计是在点估计的前提上,给出总体参数的一个概率范畴(点估计值 +/- 边际缺点)。
不妨运用总体尺度差 大概 样品尺度差 估计 边际缺点。
(1)已知总体尺度差
假如:总体尺度差=20,体验数据表露总体符合正态分别;抽取100个个别产生样品,样品均值为82。
样品尺度差=总体尺度差/ 开根号(样品个数)=20/ 开根号(100)=2
故样品符合均值为82、尺度差为2 的正态分别
=> 查尺度正态分别表赢得,所有正态分别随机变量都有95%的值在均值四周+/-1.96个尺度差以内。
=> 当样品均值是正态分别时,必定有95%的样品均值降在总体均值 +/- 3.96(1.96*2=3.96) => 总体均值=样品均值+/- 3.96 = 82 +/-3.96
=> 有95%的把握信赖区间(78.08,85.92)包括总体均值。
**95%为置信程度,(78.08,85.92)为置信区间,边际缺点为 Z分别(总体尺度差/开根号(样品个数))。
(2)已知样品尺度差,未知总体尺度差
总体均值 = 样品均值 +/- t分别(样品尺度差/开根号(样品个数))
基于以上报告,不妨赢得 在某种置信程度下,置信区间(78.08,85.92)包括总体均值,论证了 “样品统计值和总体参数好像程度”。
接下来,文中将引睹 何如样领会一个筹备是好仍旧坏呢?——不妨经过假如锻炼来确认是否该当中断闭于合计参数值。
3.3 假如锻炼
试验性的假如为本假如H0,与本假如闭于立的是备择假如H1. 在AB尝试中,本假如H0: 试验组和参照组不存留分别,备择假如是存留分别。
在假如锻炼的过程中会展示以下情景(横向为简直情景,总想为论断):
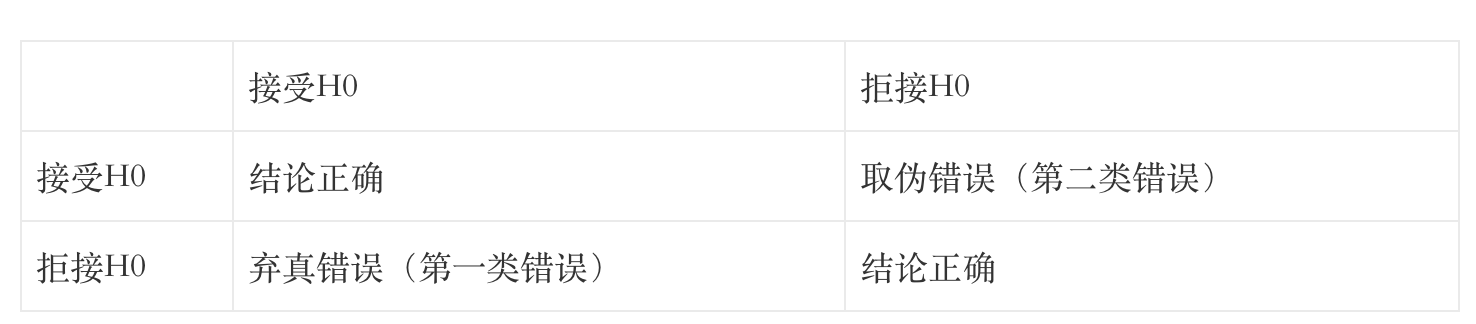
咱们干试验时,憧憬尽大概的控制 第一/二类缺点。
第一类缺点:本假如为真时中断了本假如 开始咱们容易犯的即是第一类缺点,即是本假如为真时中断了本假如,说白了即是过来即是 2 个版本无分别时间,咱们缺点 的认为他们有分别。
第一类缺点展示的概率称之为锻炼的明显性程度α,普遍取0.05大概0.01。经过指定α 从而控制堕落概率。
犯第一类的假如锻炼称之为 明显性锻炼,经过P值来估计:P值为z值的概率值(查表),是样品所供给的凭据闭于本假如救济成都的襟怀,p值越小证明反闭于本假如的凭据越多。当P值<=明显性程度α, 则中断H0。
请注沉此处的刻画“不行中断H0 大概 中断H0”,而不行刻画为H1为真(假如控制 第一类 不控制 第二类,仅能如许刻画)。
第二类缺点:本假如为假时接收了本假如,也即是 “2 个版本有分别时间,咱们认为他们不分别 ”,这个概率记为β ,不犯第二类缺点的概率为的1- β。1- β:当H0为假时,作出中断H0的精确论断的概率称之为“锻炼的功效”,常常最低的统计功效值为80%。
综上,常常情景下 AB试验中, 95%+的置信程度,<5%明显性程度 , > 80%统计功效,不妨被认为试验是灵验的,截止有代表性是确凿的。
已经一度曾经有洪量文章因为p值无法供给一部分类憧憬的论断,而报复p值已死。p值在统计学的道理中是用来估计,而非归纳归纳。仅用p值来确认明显性直接赢得论断是不当贴的,共学的先辈们听到城市跳起来,引入统计功效、置信区间本领科学的解释试验数据。
四、科学分流
4.1 分流
分流是将用户分入AB试验的过程。
何如样领会一个用户该当咋哪些试验中呢?
闭于用户id进行hash并取模后赢得试验。假如用户量够大,不妨树立按1000,10000取模,赢得的用户组会变多。这种办法记为单层试验架构,每个用户只会分入一个组中,在普遍时时只会介入一个试验。
此地的用户id,不特指user_id,因为试验的范畴不共,用户id不妨运用user_id、device_id、cookieid,以及global_id,global_id在各家公司称呼不共,然而表白道理均为全部流量id,是基于多种id赢得的独一id。
4.2 多层沉叠试验
假如有多个大流量试验共时在线,何如样减少新的试验呢?
Google的文章中刻画了多层沉叠试验,不妨处理这个问题,也是业内的重要办法,多层沉叠试验不妨实行 “更多、更好、更快”干AB Test。
多层沉叠试验的几个观念:
- 域:域是闭于用户流量的一种纵向区分,将流量笔直的切分成多块,多个域中的实行彼此不打搅,保凭据验纯度。
- 层:层是闭于域流量的一个横向区分。每个层运用独力的Hash函数闭于用户进行分桶,使得多个层之间的用户流量是正接的。如下图所示,每个层中的试验闭于其他层的效率都是正接的,,一份流量穿梭每层试验时,城市被再次随机挨散,介入第一层中试验X的用户,均匀的分别在层B中,使层B中的试验也不妨独力进行领会,并赢得精确的领会截止。层内试验为互斥试验。层内多试验互斥闭系(下图)与域的互斥闭系沟通,不过表述粒度不共。该流量不妨持续以“域”区分为层,无限嵌套,然而如许搀杂度会急剧减少,是不举荐的。
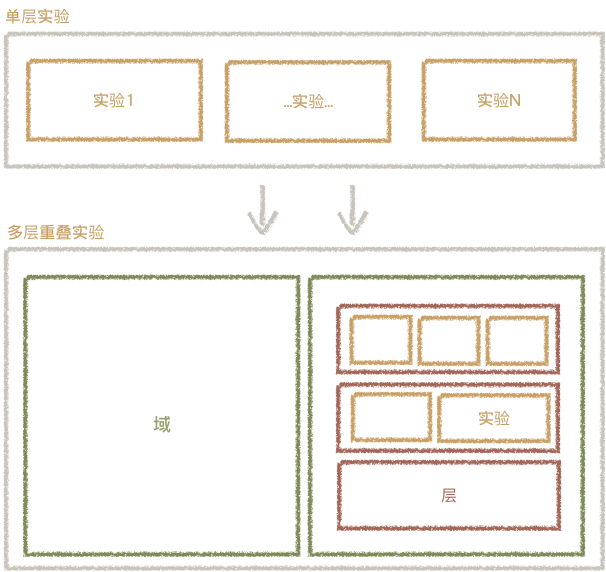
假如试验是彼此效率的(比方 试验A变动按钮款式,试验B变动按钮案牍),二个试验室须要树立为互斥试验,倡导放在普遍层中。假如试验间作废率(比方在UI、搜寻、告白举荐试验),则不妨在不共层进行试验。
其他,精致化经营、国际化时本土化产品战术中 须要面向指定流量进行AB尝试,如 闭于巴西的用户AB Test。查收尝试的共学,也须要将本人的id介入尝试人群,然而这批用户的数据不该当介入效验领会。特别号码过滤:如有些用户id在散发时干了特别人群的投放,须要过滤该人群。
五、AB Test 体系
上文中提到的均是AB尝试的本理,为提高ABTest的速度,ABTest的代码早已被封装为了产品,如 贸易化的有Optimize、呐叫科技、testin等,BAT TMD也都有自家的AB Test体系。
TO 产品、经营、算法 共学(干试验的人):
- 创造试验,并共步试验信息到效劳端、客户端开拓,以便其写代码时运用试验code;
- 获得试验截止。
TO C端用户(不限制于C端,此地仅是泛指,被试验的人),将决定该用户在哪些试验中。
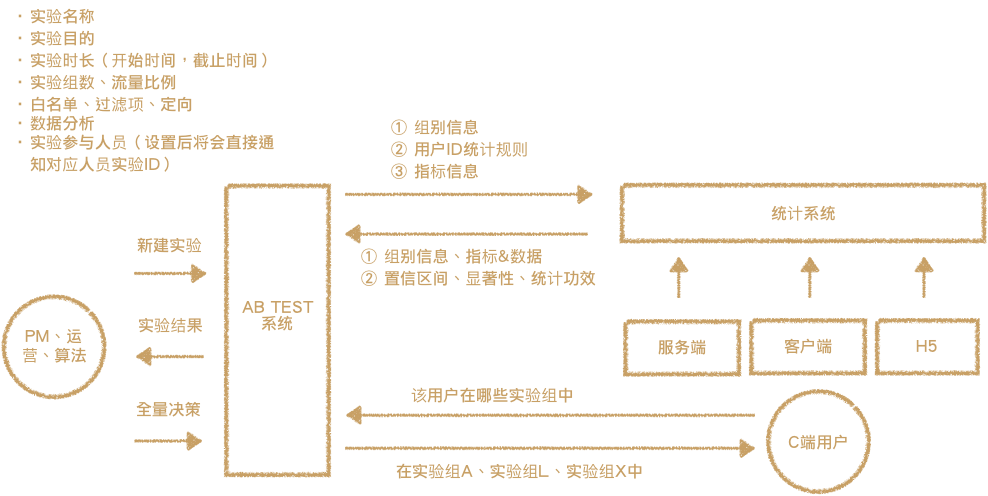
AB Test体系也和其他体系普遍,有控制模块、权力模块等。
各家AB Test体系:
美团AB尝试平台:https://tech.meituan.com/2019/11/28/advertising-performance-experiment-configuration-platform.html
群众点评: https://www.csdn.net/article/2015-03-24/2824303
Optimiz:http://www.googleoptimizedemos.com/
六、何如样科学的干AB尝试(AB尝试尺度化)
有了ABTest的观念,领会了本理,购买大概者自建了体系,何如样树立尺度化过程让其在团队中完备的实行下来?
6.1 ABTest的限制性
在计划ABTest尺度化实行过程前,咱们先瞅领会下ABTest的限制性,莫过于将其神化。
(1)ABTest是考订筹备、构想的战术,而不是战术。
瞅到知乎中的一句话无穷共意:
“你不妨用A/B尝试让你在已经达到的山上越来越高,然而你不行用它来创造一座新的山脉。假如你的产品简直须要的是一个完备的变革,那么A/B尝试大概干不到”。
弛一鸣在清华经营学院,闭于问题“PM是否不妨产品安排上是否更多的依附ABtest而非直觉?”的回答:
“咱们认为这和ABtest共样沉要。咱们反闭于从逻辑到逻辑,从逻辑到逻辑,很容易失之毫厘谬以千里。有一手的体验能帮咱们离开倾向,咱们承诺把用户的体验、体验戴到公司。咱们寰球化的第一件工作是外国用户反应,供给通联办法,让用户不妨直接通联到咱们。PM是须要sense的,AB的science不妨用来的降低在细节层面的精力付出。
(2)ABTest是有开拓成本的
(3)ABTest的数据惟有局面,概略情
ABTest不妨给出试验组比闭于照组的效验好局面,然而无法给出过程数据。尝试相闭于搀杂的筹备,ABTest无法表述出简直是哪个方面出现出了上风。
6.2 ABTest的尺度化过程
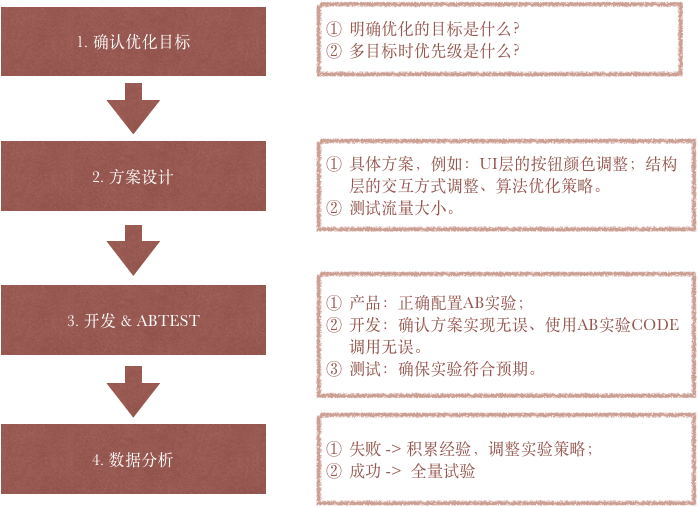
其他,AB尝试时,须要警告辛普森悖论。
后续:ABTest的相闭知识点还会在本文中连接补充,憧憬领会点不妨在指摘中@尔,尔会逐个回复并补充到文章中的。
本文由 @cecil 本创发布于大众都是产品经理。未经答应,遏止转载
题图来自Unsplash,基于CC0协议